#+BLOG: rubikitch
#+POSTID: 1847
#+DATE: [2016-12-05 Mon 20:11]
#+PERMALINK: language-detection
#+OPTIONS: toc:nil num:nil todo:nil pri:nil tags:nil ^:nil \n:t -:nil tex:nil ':nil
#+ISPAGE: nil
#+DESCRIPTION:
#+BLOG: rubikitch
#+CATEGORY: 解析ツール
#+EL_PKG_NAME: language-detection
#+TAGS:
#+EL_TITLE:
#+EL_TITLE0: elispでプログラミング言語を自動判定できるってホント?
#+EL_URL:
#+begin: org2blog
#+TITLE: language-detection.el : elispでプログラミング言語を自動判定できるってホント?
[includeme file="inc-package-table.php" name="language-detection" where="melpa"]
#+end:
** 概要
language-detection.elは、バッファや文字列の内容から
プログラミング言語を判定するライブラリです。
M-x language-detection-bufferはカレントバッファの言語を判定し、
エコーエリアに出力します。
内部では language-detection-string 関数が使われており、
文字列のトークンのパターンからプログラミング言語を判定します。
さすがにすべてをEmacs Lispで処理するのは荷が重いです。
そこで、 scikit-learn という ランダムフォレスト による
機械学習Pythonライブラリによって
巨大な学習データとEmacs Lispコードが作成されています。
MELPAでインストールされる段階ではすでにデータが作成されていますので、
実行時には外部プログラムに依存しません。
Emacs Lisp側では正規表現によるトークン作りと
ハッシュテーブルと配列によるアクセスだけですので
実用的な速度で動作します。
言語判定はlanguage-detection.elだけでなく、
Highlight.js や Pygments や SourceClassifier がありますが、
language-detection.elはそれらすべてを上回る精度(73%〜87%)です。
判定のために使われた情報源は
- Stack Overflow
- Rosetta Code
- Github Linguist
です。
[includeme file="inc-package-install.php" name="language-detection" where="melpa"]
** 判定例
#+ATTR_HTML: :width 480
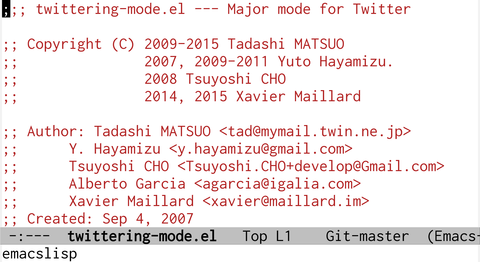 Fig1: twittering-mode.elは正しくemacslispと言ってくれる
#+ATTR_HTML: :width 480
Fig1: twittering-mode.elは正しくemacslispと言ってくれる
#+ATTR_HTML: :width 480
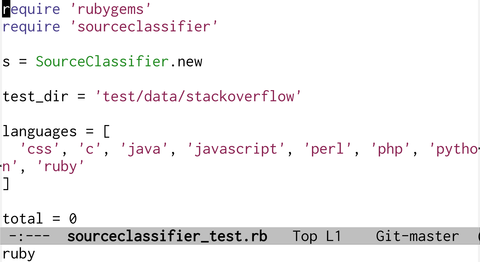 Fig2: sourceclassifier_test.rbも正しい
#+ATTR_HTML: :width 480
Fig2: sourceclassifier_test.rbも正しい
#+ATTR_HTML: :width 480
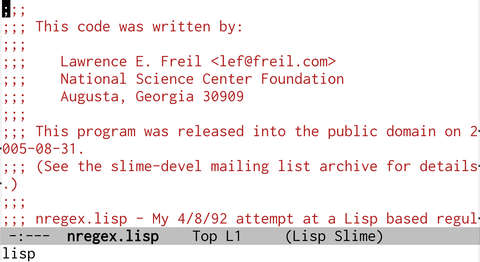 Fig3: Common LispやSchemeはlispと判定する
#+ATTR_HTML: :width 480
Fig3: Common LispやSchemeはlispと判定する
#+ATTR_HTML: :width 480
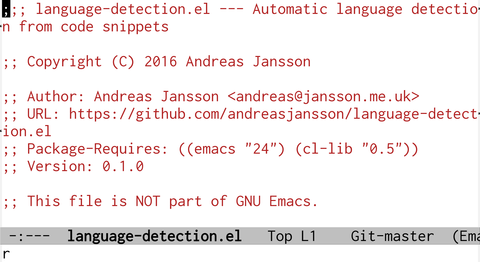 Fig4: language-detection.elは後半に巨大な配列があるせいかR言語と誤認してしまう(笑)
** 対応言語
- ada
- awk
- c
- clojure
- cpp
- csharp
- css
- dart
- delphi
- emacslisp
- erlang
- fortran
- fsharp
- go
- groovy
- haskell
- html
- java
- javascript
- json
- latex
- lisp
- lua
- matlab
- objc
- perl
- php
- prolog
- python
- r
- ruby
- rust
- scala
- shell
- smalltalk
- sql
- swift
- visualbasic
- xml
[includeme file="inc-package-relate.php" name="language-detection"]
** 参考サイト
- ランダムフォレスト - Wikipedia
- scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation
Fig4: language-detection.elは後半に巨大な配列があるせいかR言語と誤認してしまう(笑)
** 対応言語
- ada
- awk
- c
- clojure
- cpp
- csharp
- css
- dart
- delphi
- emacslisp
- erlang
- fortran
- fsharp
- go
- groovy
- haskell
- html
- java
- javascript
- json
- latex
- lisp
- lua
- matlab
- objc
- perl
- php
- prolog
- python
- r
- ruby
- rust
- scala
- shell
- smalltalk
- sql
- swift
- visualbasic
- xml
[includeme file="inc-package-relate.php" name="language-detection"]
** 参考サイト
- ランダムフォレスト - Wikipedia
- scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation